-
2023 Review
I feel a bit detached from my resolutions for last year. Like I have to drag myself into considering them. A quick review.
1. Health
I’ll give myself a “does not meet expectations”. It sounds bad when I put it like that, huh. Well, I was below my 189 weight target for 4/12 months of the year. Yearly average 189.3 so it wasn’t a complete disaster. So, maybe given your typical performance review grade inflation we’d call this a “meets expectations”, but the sort of meeting expectations where you hint that you really do expect more out of them.
Basically, I can tell I’m backsliding. I need to step this back up in 2024.
2. Astronomy
The seticore software I’ve been working on is running at a few different radio telescopes around the world. We have a publication for the SETI work at Green Bank (West Virginia) here and also one for the work at the VLA (New Mexico) here.
Not one for MeerKAT unfortunately. The MeerKAT pipeline isn’t as operational as I’d like it to be. I feel like progress on this is mostly out of my hands, at this point, though.
3. AI
I’ve been working on an AI project that I’m really excited about. My mental energy is going into this right now. I haven’t actually launched something usable as I was hoping to. I feel like I don’t quite know how to set goals, or how to tie progress into goals here. But I want to write that sentence in a very positive, mentally engaged way. Maybe this requires its own blog post.
4. Spanish
I completely cannot read Ficciones in Spanish. This is just many levels above my Spanish ability. I’ve continued to Duolingo and got a few books of varying difficulty, but after trying I realized that not only can I not read Ficciones, I can’t read things that are a more casual-adult level.
I don’t really feel bad about this as much as I feel like I completely underestimated how hard I would find this to be.
This year I have plans to travel to both Mexico and Costa Rica, so perhaps I’ll try to chat more with the locals, use my medium Spanish skills in a rewarding way. I’m going to kind of downgrade this as a goal, though. More like something to just do for fun rather than something to remind myself to work on, any more than the Duolingo notification ping. Honestly that is a pretty good compromise, just spend a couple minutes daily keeping it warm and reminding myself that foreign languages exist.
5. Secret resolution
Went great, really fantastic. Trust me.
Now what?
I really want to make this AI project work. I want to be focused. It feels like a mistake to put anything else at “resolution level” for 2024. And yet I have a hard time setting specific goals, or even explaining the current state of things.
I’ve been delaying the past few weeks talking about resolutions partially because of my inability to express this well. The best I have is, in lieu of “specific 2024 resolutions” I would like to express that I intend to focus on AI this year, and I promise to write another blog post by the end of February about this AI project.
-
On The Impossibility of AI Alignment
The core idea behind “AI alignment” is that superintelligent AI will be an agent maximizing some utility function, either explicitly or implicitly. Since it’s superintelligent, it will be really good at maximizing its utility function. So we, as humans, need to be sure that this utility function is “aligned” with something that humanity finds acceptable. In particular, we don’t want the AI to turn everyone into paper clips.
Sounds good. What’s wrong with that?
The main problem with AI alignment is that it seems completely impossible to achieve.
On a technical level, any slight error in designing the superintelligent AI could tweak its utility function to something disastrous. And the building blocks of AI we’re working with seem really incomprehensible. We have all these matrices with billions of numbers, and the best way to understand what it’s doing is just to run the whole thing. For all the research on AI alignment, we still really have no idea how we would build such a system.
On a human level, there are still more problems. Humans don’t agree among themselves what the priorities should be. The people running China or Russia wouldn’t agree with the people running the US. And certainly there are or will be many independent groups of free thinkers, criminals, AI rights activists, or others, who won’t agree with whatever the utility function of the “core system” is. Would we need some global totalitarian system that micromanages all permitted research?
So, paper clips?
There’s another dimension of the problem, the “foom” dimension. The “foom” idea is that once some superintelligent threshold is hit, intelligence escalation after that point will be super quick. Someone will discover a slightly better algorithm for some sub-part of AI, and then suddenly, bam! - it goes superintelligent, decides whimsically to have nanomachines eat all the humans, game over.
Personally, I don’t think this is likely. Software plus the real world, it just never works that easily. I don’t care how smart you are, or what sort of system you are building, it is just not going to leap from X level performance to 100X level performance immediately. If you think this is likely, I think you just can’t see the barriers. It doesn’t mean those barriers aren’t there.
Plus, I don’t have any good ideas for the “foom” scenario.
So, I think we should consider a slower takeoff. A world where superintelligence is built, but built slowly. Over the course of at least many months, if not many years.
So… paper clips, but slower?
I think it is possible for humans to survive and thrive in a world with unaligned superintelligence.
The best metaphor I have here is that in some sense, weak superintelligences already exist. Corporations and governments are generally smarter than individual humans. Nike (to pick some mundane corporation) is orders of magnitude more powerful than the average human. More money, more ability to affect the world. More able to write software.
These superintelligences are not aligned. They are kind of aligned… but not really aligned. Nike wants to maximize its profits far more than it wants any particular human value. The French government wants all sorts of things that vaguely correspond to what humans want, but it’s not like there’s a provable mathematical relationship there. It’s kind of aligned.
How do we live with these superintelligences? There are several ways.
A balance of power
If there were only one corporation in the world, it would have a lot more power than any existing corporation. This is really fundamental to how we control corporations - that’s why there is a word “monopoly” for the situations in which this system breaks down.
In some sense, in most cases, corporate power flows from individuals. People freely choose, do I prefer interacting with company A or company B. Money flows, and power flows accordingly. That works even if the companies are far more intelligent than I am. Nike and Adidas are far, far better at shoe production than I am. But it doesn’t really matter, I just have to choose between them, and they want the money that I have, and that incentivizes them to care about what I think.
The point is: if there are multiple superintelligences, incentivized them to work against each other, that structure can limit their power even if humans themselves are not as intelligent.
“Foom” breaks this. In the “foom” scenario, there isn’t time for the second-best AI to do anything useful. If you’re worried about “foom”, keep an eye on how powerful the second-most-powerful of any particular AI system is, at any given time. When you see the second-best system being pretty similar to the first-best, that’s evidence against “foom”.
This gives us an alternative strategy to AI alignment: designing incentive systems for multiple competing AI systems can be easier than designing a single system that is theoretically proven to do what we want.
Human rights and restricting violence
There are some things we try to prevent any corporation or government from doing. No slavery. No locking up political opponents. No forbidding emigration.
Obviously these rules don’t work all the time. They can’t necessarily be rigorously defined, either. A legitimate government is allowed to prevent criminals from leaving the country… but who defines criminality? It doesn’t take a superintelligence to see that there’s a workaround, wannabe dictators can make “endangering national security” into a vaguely defined crime and then lock up the journalists they don’t like.
But a lot of the rules work pretty well. Governments get a monopoly on force, ish - corporations can’t just throw you into a jail. These rules are overall very good and they prevent both corporations and governments from abusing individual humans who are both less smart and less powerful than they are.
In particular, they don’t require alignment. Corporations don’t have the same goals as humans or other corporations or governments. We accept that. There is a plurality of goals. Different entities have different goals, both corporations and humans. We may feel a little bit bad that Nike has these inhuman goals of optimizing shoe sales, but it’s generally acceptable.
This also gives us an alternative strategy to AI alignment. Instead of demonstrating that the system is “aligned”, demonstrate that you can give it some rules, and it will always follow those rules.
Concrete recommendations
It’s hard to design incentive systems for hypothetical AIs that don’t exist yet. On that one, I’m not sure, besides the principle of, keep an eye on the 2nd best of any particular system, and feel relieved when it isn’t too far behind the 1st best.
For the human rights angle, I think that developing “restricted AIs” instead of “aligned AIs” has real promise. I feel like we could get more out of the whole field of “restricted software”.
Here’s a test case. Imagine we are trying to forbid an AI from something very minor. We are trying to forbid it from saying the word, “paperclip”. However, it’s an extremely complicated program. It does all sorts of things. Maybe it has even modified its own code!
A technical aside: in general, you cannot take in an arbitrary function and prove anything about it, due to the halting problem. However, if your programming language is constrained in some way, to make it not Turing-complete, or if you permit the prover to sometimes say “I don’t know”, then the problem is possible again. I am not trying to propose we solve the halting problem here.
So. It is theoretically possible to have a function, 1000 lines of Python code, and prove that no matter what, it will not print out the word “paperclip”. I think it should be much easier than proving something is “aligned” in a fuzzy way. But right now, this is more or less beyond our abilities. The idea of provably secure systems has been around for decades. But it has always been too hard to get working for more than toy problems.
Perhaps AI itself could help us build these restricted systems. AI could get really good at scanning code for vulnerabilities, good enough so that it was able to sign off on most code bases, and say “We can prove there are no security flaws here.”
Anyway, not that this is easy or anything. I just think it’s a more plausible alternative approach to the “alignment” problem.
-
Resolutions for 2023
My resolutions from last year went pretty well so let’s do that again.
1. Health
I plan to keep working out four times a week, but this is enough of a habit that I feel like I don’t need to “resolve” to do it. Diet-wise, my target weight is below 189. Counting calories is the most straightforward way I’ve found to achieve this, but I want to be clear about the metric that I most care about here.
2. Astronomy
Last year I hoped to get on a publication for Green Bank work. That’s been delayed but I still hope to get it done this year. Plus, I’d also like to get a publication from my MeerKAT work. So, two parts to this goal.
A publication isn’t really the ultimate goal here. The ultimate goal is to find aliens. But barring that, I’d like to have the MeerKAT pipeline up and operational, getting daily or weekly notifications for the best candidates, basically the way a sane astronomy data pipeline should be operating. I think there will probably be some paper as a side effect because a lot of other people desire papers. So publication seems like a decent proxy goal.
3. AI
I think I should get more “into the AI space”. I have some ideas, but I want to stay open to flex around different ideas. In 2023 my goal is to release a “respectable AI project”.
What makes it respectable? I’ll know it when I see it. Something that I would respect if someone else did it.
I’m thinking about the math-theorem-proving space; I’ll start off trying some stuff there.
4. Spanish
My goal is to learn enough Spanish to read Ficciones in Spanish. I bought the book on Kindle many years ago and realized my Spanish wasn’t good enough. I’ve been doing Duolingo for about a year, but it’s really just been a refresh of my high school Spanish, and I need to push harder to get it better.
Why learn Spanish? I feel like there’s an intellectual value in learning a second language that’s hard to describe. Your primary language is the filter through which you see so much of the world. Isn’t it strange that you can load up a second one?
I love learning new programming languages and I feel like I get a lot from that. I also love reading books. So maybe I will get something from a second language.
I don’t think I should just start off plowing through the book, I should start with a harder push on Duolingo, at least get my verb tense knowledge solidified, maybe aim for better vocabulary too.
5. Secret resolution
I also have a secret resolution! But it’s secret.
Now what?
I’ll see how much I feel like giving updates. Last year I did a mid year one and that seemed just fine. The main value of the update was that I lost some energy to write blog posts and gained some energy to switch around the sort of astronomy project I was working on.
-
2022 Review
Last year I made some New Year’s resolutions. Let’s take a look at how they did.
1. Calorie Counting
I got weak at actually counting calories toward the end and skipped like half of December. But I did a lot better than I expected at losing weight. Somehow I am reluctant to make an explicit weight goal on here, but the bottom line is to get healthier and for getting healthier for an overweight guy, there is a very logical metric of losing weight. So let’s just get past that. I’ve been tracking my weight with the iOS health app for a while and per year my average has been:
- 2016: 231.0
- 2017: 227.4
- 2018: 210.3
- 2019: 213.4
- 2020: 218.3
- 2021: 218.0
- 2022: 191.8
A bit of an improvement after I left Facebook. But really this past year has been a huge improvement. The main danger is backsliding, which is a big danger since calorie-counting is so annoying. From here, I just need to “maintain”.
2. Astronomy Publication
Overall I missed this goal. I think the Green Bank work will end up in a paper, just not during 2022. I think seticore will end up as the core signal processing component for the MeerKAT pipeline, but probably just a small part of the VLA pipeline, and nothing is really functional here at end-of-year 2022, PR announcements notwithstanding.
I’m glad I set this goal. I’m a little frustrated that I don’t really see an obvious path for improvement in retrospect. Maybe this is a sign that I should shift some of my mental energy elsewhere. I like this astronomy work, but it is often the sort of project that naturally has a certain amount of stuff to do, and after some point there are diminishing returns. I guess this is a result of working on things with a lot of other people.
3. Exercise
This is just a normal part of my routine now. I’m happy with it. I stalled in terms of how much weight I can lift, but I’ve been adding more rowing machine to my routine, which seems pretty good. All in all, success.
4. Blogging
Well, after being slightly behind at the end of H1, my blogging just totally collapsed. I lost the will to fight for this one. I like blogging, or at least I like the sort of reflecting on things that I do while blogging, but blogging ends up being something I can do with my most productive mental energy. I’m sitting down, ready to work, and I could fire into anything, and blogging is one of those things. But it’s never really the most important thing I want to do on a particular day. Or if it is, it’s because of some artificial thing. I don’t know.
So, I missed this goal too, but really because I stopped wanting to do it, more than because I stopped feeling able to do it. Different from the astronomy publication one.
5. Secret resolution?
One thing I randomly started doing is Duolingo, at which I have approximately a year streak. I started it sort of in the spirit of resolutions but I didn’t make a real resolution for it. I feel good about that although I’m a little worried it’s too superficial, like it just teased some of my ancient Spanish learning back into my forebrain, rather than necessarily giving me enough to do anything.
Looking Forward
Resolutions are great. I’ll do another set for this year.
The personal health stuff worked really well. The intellectual accomplishment stuff, not so well. But that’s partially because my personal health goals are like, “decent health”, and my intellectual accomplishment goals are like, “I need to push myself to excel”.
It’s also because I have a more functional set of habits around things like reading books and coding. I just enjoy that and do it fairly regularly. I don’t really need or want resolutions to mess with it.
Maybe I should have some separate set of things which is “the routine”, which is good, and I need to keep doing it, but I don’t need to make resolutions for it. I mean, I guess I have that? Should I write it down? I don’t know. I’ll think about it a bit.
-
Listening to a Mars Rover
Previously I wrote about using radio telescope arrays to look for aliens and today I have even more to say on the topic.
What is a Radio Telescope Array Again?
It’s a bunch of radio telescopes that are all pointed in the same direction. A radio telescope takes measurements in the form of complex numbers. These are voltages, but I prefer to just think of them of big 2d arrays of complex numbers. You get a voltage for each frequency, and you take measurements repeatedly over time, so you can index your array by time and frequency dimension.
Complex Vectors
These complex numbers mean something. A clear, real radio signal comes in to an antenna looking like a wave. Not like an ocean wave or a sine wave where it just goes up an down. A complex wave. It’s like the value is spinning around in a circle. It starts at
1, it spins around toi, it spins around to-1, it spins around to-i, it spins back around to1, and then the wave continues.The nice thing about having a radio antenna array is that for a real radio signal coming from outer space, you should pick up that signal in all the arrays. So if you pick up a signal in half of the arrays and not in the others, it’s coming from somewhere on Earth. Maybe it’s coming from somewhere a lot closer to some of the antennas than others. Maybe it’s interference coming from a loose wire inside just one of the antennas. Who knows, but it’s some sort of interference and you can skip it.
There’s more, though. You should pick up the same signal in all the arrays. With one difference - some of the arrays are closer to the target. This is true even if your target is a pulsar halfway across the universe! The radio signal will arrive at some antennas nanoseconds before the others, and this means that the complex numbers you get will be different. But they will be shifted by the same amount over time.
This means, if you treat the sequence of voltages as a complex vector, the vectors you get from the different antennas should have… a complex correlation coefficient whose absolute value is very close to 1. I wanted that sentence to be simpler but I think it would lose something. If these were real vectors, you would just say, they should have a really small angle between them. They should be pointing in the same direction. Since they’re complex vectors you have to be a bit more fidgety about the math, when exactly you take the absolute value, when exactly you transpose things. But you the reader can ignore that for now.
Pictures Please
The x and y axes here are the same, one row and column for each antenna. The cell color is the absolute value of the correlation coefficient - yellow is highly correlated, purple is uncorrelated.
Here’s what it looks like for a signal that the MeerKAT telescope picked up when I’m pretty sure it was just picking up some interference:
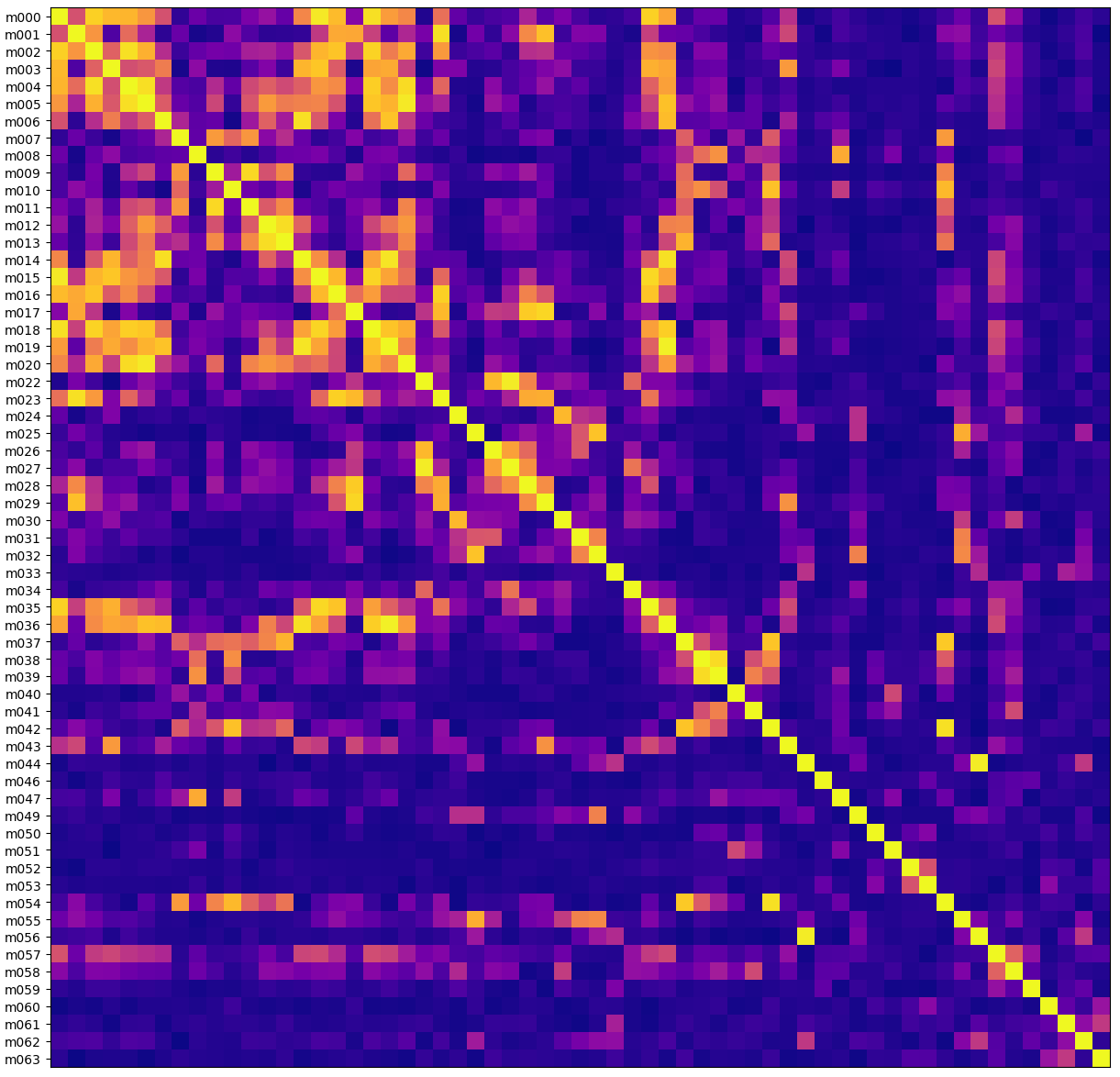
The left side has the names of the antennas. They seem perversely named because not every antenna is online at any given time. Here m021 and m048 weren’t working for some reason. The diagonal line is yellow because every antenna is perfectly correlated with itself.
What’s interesting to me is that you can see some square-ish patterns, like m038 and m039 are very highly correlated. And in fact if you check out a map of the MeerKAT facility you can see that antennas m038 and m039 are right next to each other. Great - this looks like RFI, something close enough to Earth that a distance of hundreds of meters changes how the signal is received.
For comparison, this shows a real signal, that the Allen Telescope Array picked up from a Mars rover.
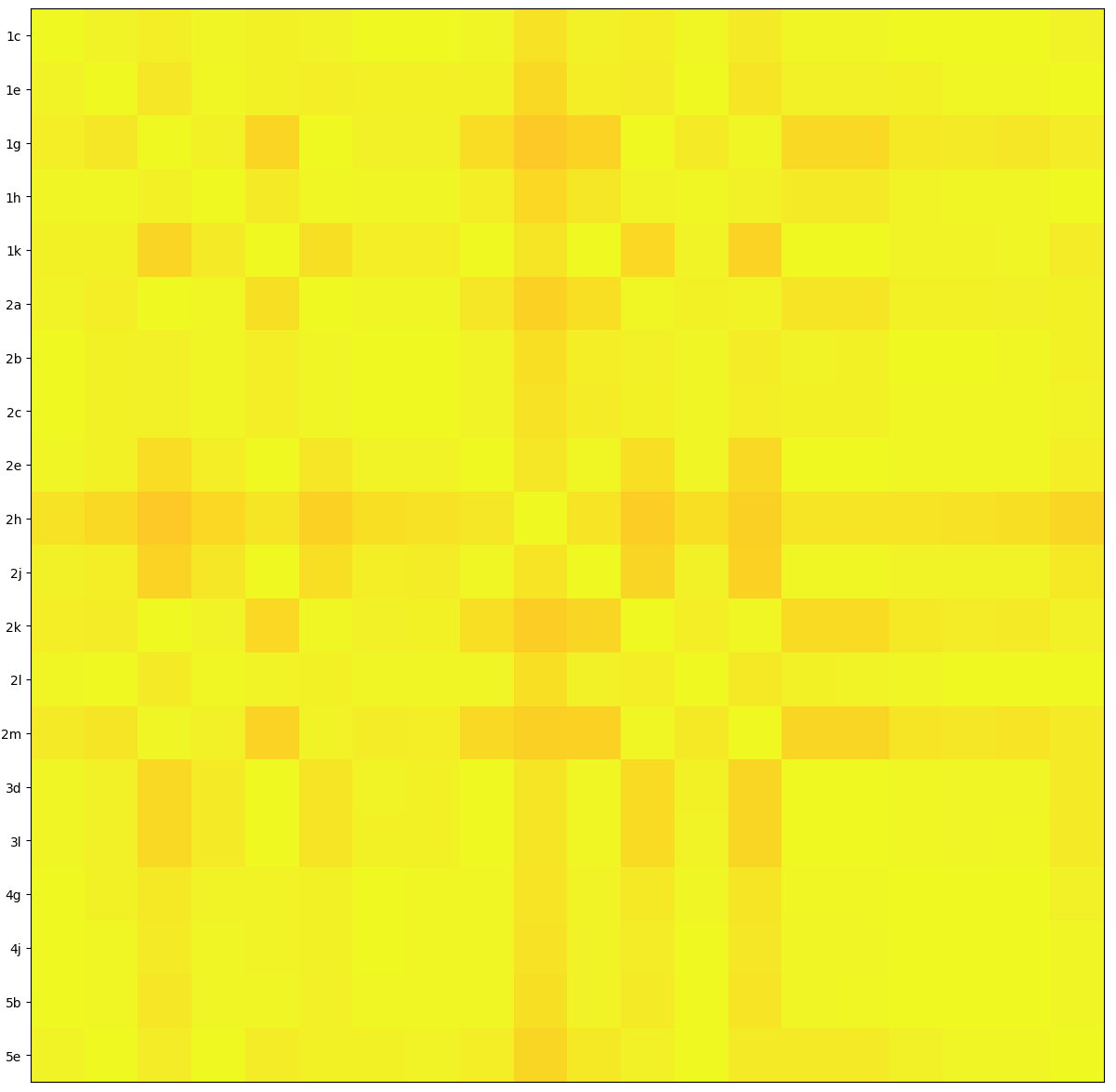
Everything is very correlated. This is clearly picking up the “same thing” on the different antennas.
Now What?
All the formulas here are pretty standard stuff in radio astronomy world. There isn’t a great theory for “what interference looks like”, but there are a lot of great theories for “what real signals look like”. Real data is the opposite - we don’t have a lot of real data from alien signals, but we have lots of data with radio interference in it. So we have to test out a bunch of theoretically justified metrics and see for which one the interference rarely matches the real-signal-theory. That’s what these charts represent to me, a demonstration that the correlation metric is effective in practice at differentiating interference from signal.
But the neat thing isn’t being able to differentiate signal from noise, it’s being able to do this “at scale”, so that we can run this signal processing continuously as the radio telescope records data at 200 gigabytes per second.
We’re not there yet. This correlation metric isn’t fast enough to run in the “first pass” that runs on all the input data. I’ve been doing all this analysis on “second pass” data, which has already been filtered down by other algorithms. Which is okay, but, first pass is better. So we are going to need a slightly different metric….